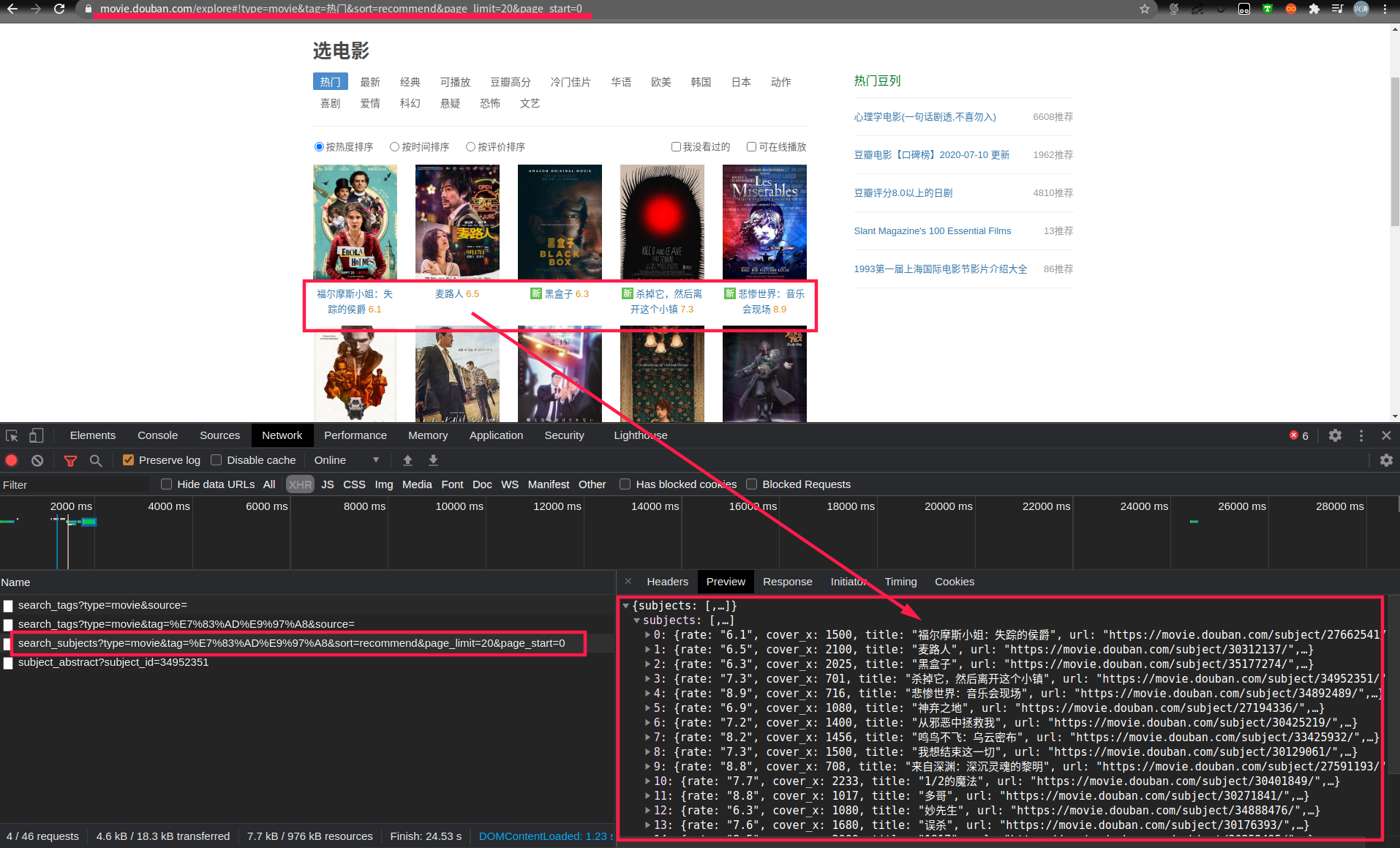
网页解析
代码解析
类初始化
class DouBanMovie(object):
def __init__(self):
self.base_url = "https://movie.douban.com/"
self.start_url = "https://movie.douban.com/j/search_subjects?type=movie&tag=%E6%9C%80%E6%96%B0&page_limit=20&page_start={}"
self.header = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"}
获取URL列表
def get_url_list(self, start_url):
"""
通过初始URL,获取所有的URL列表
:param start_url: 初始URL
:return: 所有URL的列表
"""
# 列表推导式
# return [start_url.format(page * 20) for page in range(10)]
# for循环
url_list = []
for page in range(10):
url = start_url.format(page * 20)
url_list.append(url)
return url_list
获取网页
def get_html(self, url, header):
"""
根据每一个URL,获取它返回信息
:param url: 单个URL请求的链接
:return: 当前URL响应中的内容
"""
response = requests.get(url, headers=header)
response.encoding = response.apparent_encoding # 编码
if response.status_code == 200:
return response.text
解析数据
def parse_url(self, html):
"""
拿到每个URL返回的信息之后,处理数据中的有用信息
:param html: URL返回的信息
:return: 每条数据中的有用信息
"""
# 处理json数据
items = []
content = json.loads(html)
for movie in content["subjects"]:
item = {}
item["电影"] = movie["title"]
item["评分"] = movie["rate"]
item["图片"] = movie["cover"]
items.append(item)
return items
存储数据
def save(self, file, items):
"""
拿到JSON数据之后,写入到CSV文件中
:param items: 装有JSON数据的列表
:return: 文件写入状态
"""
try:
# 写入csv文件
with open(file, 'a+') as csv_save:
field_name = ['电影', '评分', '图片'] # 表头
writer = csv.DictWriter(csv_save, fieldnames=field_name)
# 多行写入
writer.writerows(items)
# 单行写入
# for item in items:
# writer.writerow(item)
# 自动获取文件的绝对路径
current_path = os.path.abspath(__file__)
file_path = os.path.join(
os.path.abspath(
os.path.dirname(current_path) + os.path.sep + "."
), file
)
return file_path
except Exception as error:
return error
运行逻辑
def run_save(self, file_name):
"""
整个类的代码逻辑
:return:
"""
url_list = self.get_url_list(self.start_url)
for url in url_list:
html = self.get_html(url, self.header)
items = self.parse_url(html)
self.save(file_name, items)
实例化对象
douban = DouBanMovie()
douban.run_save("douban.csv")






评论区