



通用请求
使用requests.Session来保持连接,这样可以复用连接,减少连接建立的开销,提高效率;
检查HTTP错误状态码,如果响应中包含HTTP错误(如404或500),会引发异常;
使用指数退避算法来处理重试间隔,每次重试之间的等待时间增加(2的指数次幂),避免对服务器造成过大负载;
打印详细的错误信息以便调试,并在所有尝试失败后返回 None。
解析返回值
HTML
XPath很好用,直接使用分析网页结构就可以获取到数据了
可以使用XPath Helper 在线解析,获取数据更方便
HTML的数据大多在列表中,先获取到上层数据,再遍历解析
使用yield返回可以利用到Python的协程特性,返回一个列表
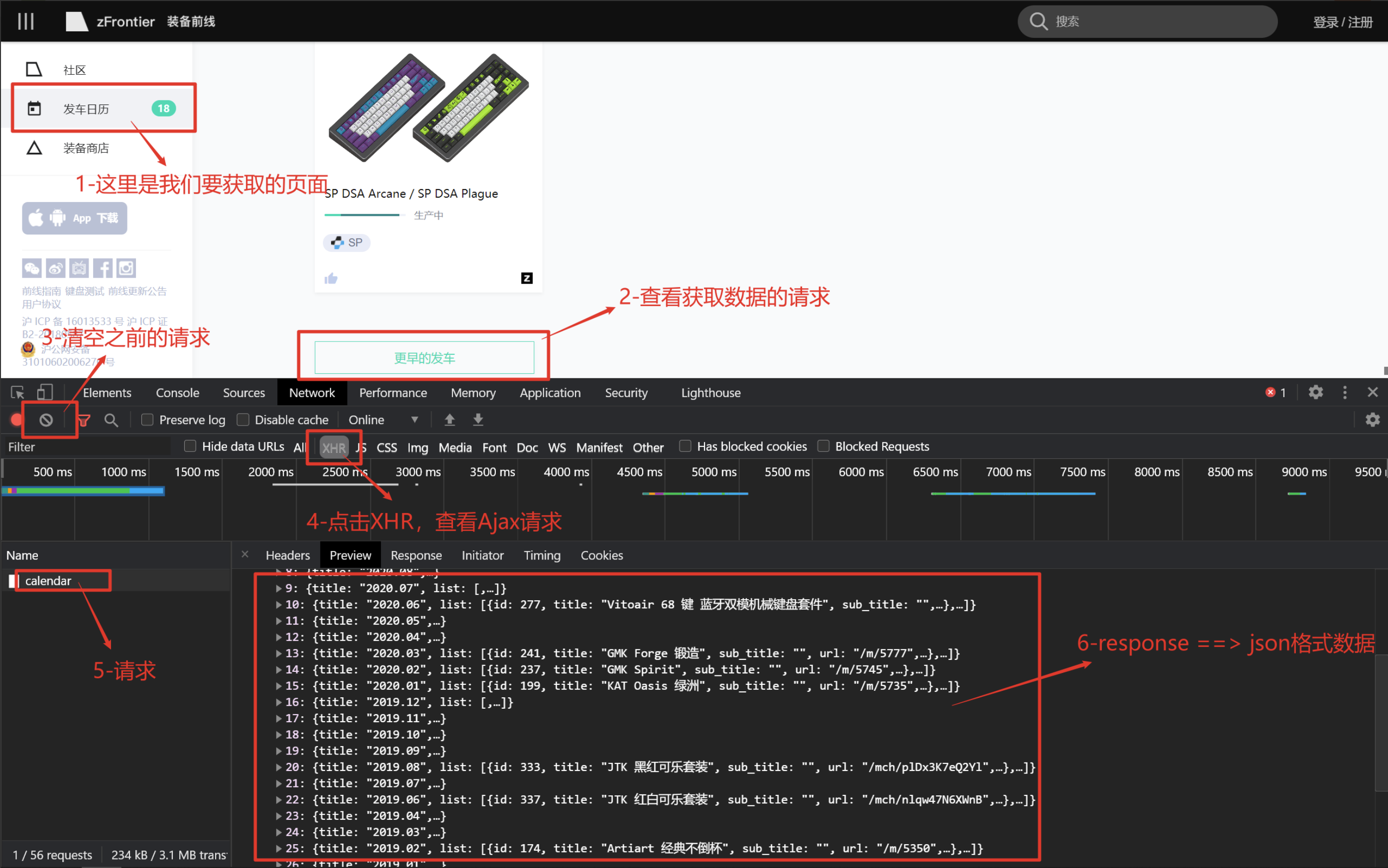
Json
直接处理json数据就可以了,将数据封装到字典中返回
同样yield返回数据,下一步解析的时候,遍历处理字典
结果处理
保存数据
写入文件
终端输出
封装
将通用数据定义在init中,避免重复定义
减少类方法的相互调用,减少各方法之间的依赖,利于拓展优化
定义run方法,编写执行流程,可以将run方法再写到init中,实例化的时候就执行
import json
import time
import requests
from fake_useragent import UserAgent
from lxml import etree
class BaseSpider:
def __init__(self):
self.base_url = ""
self.headers = {"User-Agent": UserAgent().random}
self.proxies = {}
self.session = requests.Session()
self.retries = 3
def get_response(self, url):
"""
获取指定URL的内容,自动重连三次
:param url: 需要抓去的URL
:param retries: 重连次数,默认为3次
:return: html、json
"""
ua = UserAgent()
session = requests.Session()
for attempt in range(self.retries):
try:
response = session.get(
url,
headers={"User-Agent": ua.random},
timeout=2
)
# 检验状态码
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
print(f"Attempt {attempt + 1} failed: {e}")
if attempt < self.retries - 1: # Not the last attempt
time.sleep(2 ** attempt) # Exponential backoff
else:
print("All attempts failed.")
return None
def parse_html(self, html_response):
"""
解析HTML结构
:param html: 网页的html
:return: 当前页的页面的信息
"""
xml = etree.HTML(html_response)
items = xml.xpath("//div[@id='content_left']/div/div/a")
for item in items:
yield {
"title": item.xpath("text()")[0],
"link": item.xpath("@href")[0]
}
def parse_json(self, json_response):
"""
解析JSON结构
:param json: 网页的json
:return: 当前页的页面的信息
"""
data_json = json.loads(json_response)
for item in data_json["data"]["groups"]:
for good in item["list"]:
yield {
"time": item["title"],
"id": good["id"],
"title": good["title"],
"status": good["status"],
"cover": good["cover"]
}
def save_data(self, data):
"""
保存数据
:param data: 需要保存的数据
:return:
"""
try:
with open("data.json", "a", encoding="utf-8") as f:
f.write(json.dumps(data, ensure_ascii=False))
f.write("\n")
f.close()
except Exception as e:
print(e)
if __name__ == '__main__':
spider = BaseSpider()
response = spider.get_response(spider.base_url)
results = spider.parse_html(response)
for result in results:
spider.save_data(result)

评论区